AI assurance: How to avoid an AI crisis with best practices in AI development [2024 update]

In this article
Last updated on 15-08-2024
Artificial Intelligence (AI) is rapidly transforming industries, but many AI and big data systems face significant quality challenges, particularly in maintainability and testability. In this article, Rob van der Veer and Asma Oualmakran explore common AI/big data system quality issues, analyze their underlying causes, and provide actionable recommendations to help organizations prevent a major AI crisis.
Software Improvement Group’s (SIG) benchmark is the world’s largest database containing over 200 billion lines of analyzed source code from tens of thousands of software systems. Last year, we looked at AI systems in particular, and our research revealed that AI/big data systems are significantly less maintainable than other systems. In fact, a whopping 73% of AI/big data systems scored below average in the 2023 Benchmark report.
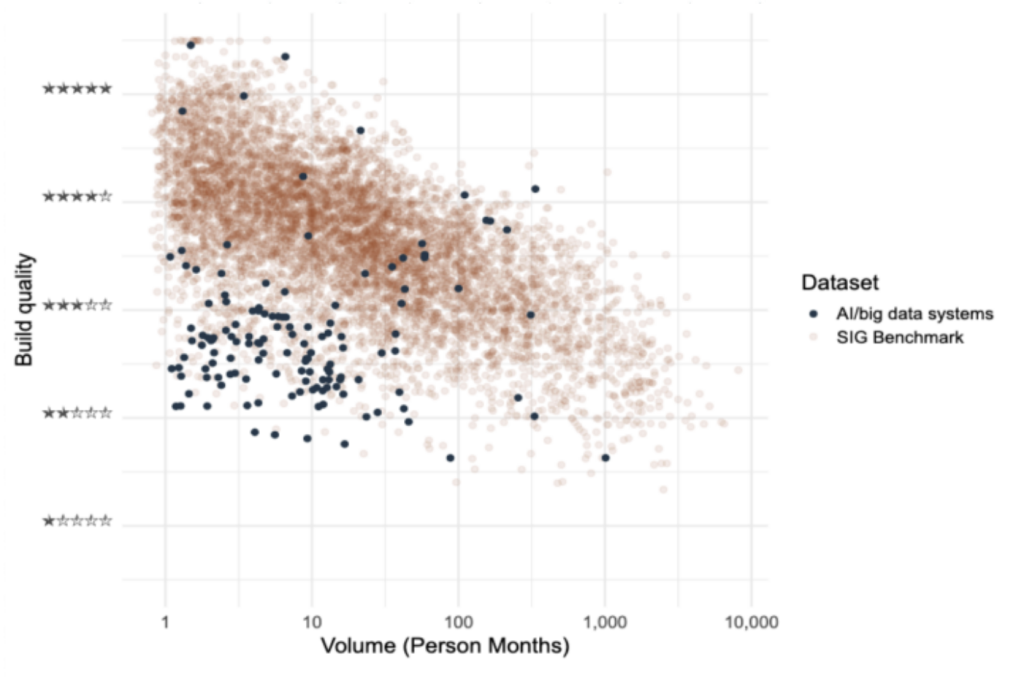
Figure 1: Our selection of AI/big data systems from the SIG benchmark was compiled by choosing systems focused on statistical analysis or machine learning. In this graph, the X-axis represents the system size measured in months of programming work, and the Y-axis shows the maintainability measured on a scale from 1 to 5 stars. 3-stars are average.
As shown in the image above, most AI/big data systems have a low maintainability score. Fortunately, the benchmark also highlights that building maintainable AI/big data systems is possible, with some systems achieving high maintainability. This prompts the question: where do things typically go wrong?
Where do AI systems falter?
When examining low-scoring systems, we often find minimal testing and documentation, along with prevalent security, privacy, and scalability issues. The primary culprits behind these maintainability challenges are long, complex code segments that are difficult to analyze, modify, and test.
Long and complex code segments are hard to analyze, modify, reuse, and test.
The longer a piece of code, the more responsibilities it encompasses, and the more complex and numerous the decision paths become. This makes it infeasible to create tests that cover everything, which is demonstrated by the dramatically small amount of test code. In a typical AI/big data system, only 2% of the code is test code, compared to 43% in the benchmark.
Low maintainability makes it increasingly costly to implement changes, and the risk of introducing errors grows without proper means to detect these errors. Over time, as data and requirements change, adjustments are typically ‘patched on’ rather than properly integrated, making things even more complicated. Furthermore, transferring to another team becomes less feasible. In other words, typical AI/big data code tends to become a burden.
Why do long and complex pieces of code occur?
These issues usually stem from unfocused code—code that serves multiple purposes without clear separation of responsibilities—and a lack of abstraction. Useful pieces of code are often duplicated rather than isolated into separate functions, leading to problems with adaptability and readability.
In addition, there’s the challenge of the lack of functional test code (‘unit tests’). One reason for this lack is that AI engineers tend to rely on integration tests only, which measure the accuracy of the AI model. If the model performs poorly, it may indicate a fault. This approach has two issues:
- The lack of function test code makes it unclear where a problem lies.
- The model might perform well, yet a hidden fault could prevent it from achieving even better results.
For example, a model predicting drink sales using weather reports might score 80% accuracy. If an error causes the temperature to always read zero, the model can’t reach its full potential of a 95% score. Without proper test code, such errors remain undetected.
Five key causes of AI code quality issues
We see the following as underlying causes of AI/big data code quality issues:
1. Lab programming
Data scientists are efficient in ad hoc experiments to develop working AI models, not intending to deliver long-term production solutions. Once the model works, there’s little incentive to improve the code, which lacks sufficient testing, risking unnoticed malfunctions upon changes. A working model should be maintainable, transferable, scalable, secure, and robust, just like the code leading to it.
2. Data science education
Data science education often focuses more on data science than on software engineering best practices. Data scientists, AI engineers, are focused on creating working models. But they haven’t been trained sufficiently to create models that need to work outside of the lab.
3. Traditional data science development
4. The SQL pattern
SQL is a standard language for managing data in databases, but its extensive use in AI/big data systems (75-90% of programming work) presents maintainability challenges. Data scientists often find this the least enjoyable and most difficult part of their work, leading to further complications. [1].
5. Siloed teams
In AI/big data systems, teams are often composed mainly of data scientists, whose focus on creating functional models can lead to a lack of software engineering best practices, ultimately causing maintainability issues.
Preventing an AI crisis in your organization
Understanding the typical quality issues in AI/big data systems is the first step toward mitigating them. Here’s what organizations can do to prevent these problems:
Continuously measure and improve
It’s recommended to continuously measure and improve the maintainability and test coverage of AI/big data systems, providing direct quality feedback to data science teams.
Have data scientists and software engineers collaborate
Additionally, combining data scientists with software engineers in teams can be beneficial in two ways:
- Data scientists learn to write more future-proof and robust code, embracing these practices as they see daily work benefits.
- Engineers new to data science can learn from the powerful paradigms and tools available for AI and big data, thereby strengthening team synergy.
Remember that AI is software
It’s crucial to view AI as software with unique characteristics, as outlined in the new ISO/IEC standard 5338 for AI engineering. Instead of creating a new process, this standard builds on the existing software lifecycle framework (standard 12207).
Organizations typically have proven practices like version control, testing, DevOps, knowledge management, documentation, and architecture, which only need minor adaptations for AI. AI should also be included in security and privacy activities, like penetration testing, considering its unique challenges [2]. This inclusive approach in software engineering allows AI to responsibly grow beyond the lab and prevent a crisis.
During our IT leadership event SCOPE 2024, I gave a keynote on how leadership can navigate AI and addressed these exact elements.
In Artificial Intelligence (AI), achieving solid engineering and code quality is challenging but crucial for success. At SIG, we’ve expanded our core capabilities to support your AI initiatives, helping you design, build, and deploy responsible AI that drives true success. Next to our expert AI assurance services, our Sigrid® platform provides the insights needed to ensure that AI systems remain maintainable, secure, and adaptable.
By continuously measuring and improving system quality, fostering collaboration, and applying established software engineering principles to AI, organizations can avoid a major AI crisis and drive long-term success. More research findings and code examples can be found in the SIG 2023 Benchmark Report.
References:
[1] Software Engineering for Machine Learning: A Case Study”, presented at the 2019 IEEE/ACM 41st International Conference on Software Engineering: Software Engineering in Practice (ICSE-SEIP) by Amershi et al. from Microsoft.
[2] For more information on AI security and privacy, refer to the OWASP AI Security & Privacy Guide: OWASP AI Security and Privacy Guide

To prevent AI crises, our AI readiness guide, authored by Rob van der Veer, outlines 19 steps for secure and responsible AI development. It emphasizes practical strategies for governance, risk management, and IT development. With a focus on testing, DevOps, and collaboration, the guide ensures robust AI integration and minimizes risk while maximizing potential.
Prevent AI-related crises before they happen. Download our AI readiness guide for actionable steps to ensure robust and secure AI implementation.


